Sakana AI Fuguとは|世界最高峰のモデルを束ねるマルチエージェントAPIの性能・料金・使い方を徹底解説
Sakana AIが2026年6月22日に公開したFuguを解説。複数のLLMを動的に束ねて1つのAPIとして提供するマルチエージェント基盤の仕組み、Fugu/Fugu Ultraのベンチマーク性能、料金、使い方、特定ベンダー依存を避けられる利点までを公式データとともに紹介します。
図の引用元: Sakana AI「Sakana Fugu」公式ページ。本記事に掲載した図表はすべて Sakana AI 公式サイトより引用しています。
Sakana AI は2026年6月22日、複数の大規模言語モデル(LLM)を動的に束ねて1つのAPIとして提供する新しいAI基盤 Fugu(フグ) を一般公開しました。単一のフロンティアモデルに頼るのではなく、内部で世界トップクラスの複数モデルを「指揮(オーケストレーション)」し、あたかも1つのモデルのように振る舞うのが最大の特徴です。
本記事では、Sakana Fugu の仕組み、Fugu と Fugu Ultra のベンチマーク性能、料金、使い方、そして「特定ベンダーへの依存を避けられる」という独自の価値までを、公式発表のデータとともに解説します。
本記事のデータ・図表の出典は Sakana AI公式発表(2026年6月22日) および Fugu製品ページ です。
Sakana Fuguとは
Sakana Fugu は、Sakana AI が開発したマルチエージェント・オーケストレーション基盤です。ユーザーから見れば1つのAPI(しかも OpenAI 互換)として扱える一方、その内部では複数の専門モデル(エージェント)をタスクに応じて動的に呼び出し、役割分担・委譲・検証・統合までを自動で行います。
- 1つのモデルのように使える: モデル選定や委譲といった複雑さはすべて内部で処理され、ユーザーは複雑さを意識せずに利用できます。
- モデルを動的に束ねる: エージェントの「プール」から最適なモデルを選び、必要に応じて Fugu 自身を再帰的に呼び出すこともあります。
- ベンダー依存を避けられる: 特定プロバイダーがアクセスを制限しても、別のモデルへ経路を切り替えて処理を継続できます。
- 長いセッションでも人格が安定: 長時間のやり取りでも一貫した応答・人格を保ちます。
Fugu は約500人のアーリーユーザーによるベータを経て、2026年6月22日に一般提供(GA)が開始されました。
なぜ今Fuguが注目されるのか
Fugu が「旬」である背景には、フロンティアモデルの供給が地政学リスクにさらされ始めた事情があります。たとえば Anthropic の最新モデル Fable 5 / Mythos 5 は、2026年6月に米国政府の輸出管理上の指示によって突如アクセスが停止されました(詳細は Claude Fable 5の解説記事 を参照)。
Fugu は、こうした「単一ベンダー依存リスク」への現実的な回答として位置づけられています。複数モデルを束ねる設計のため、あるプロバイダーが使えなくなっても、エージェントプールを組み替えてフロンティア級の性能を維持できる——これが Sakana が掲げる「AI主権(AI sovereignty)」の考え方です。
Fuguの仕組み(マルチエージェント・オーケストレーション)
冒頭の図のとおり、Fugu は LLM プール(クローズド/オープンの各モデル、および Fugu 自身)を「指揮者」として束ね、タスクを最適なモデルへ振り分けます。その中核は、Sakana AI が ICLR 2026 で発表した2本の研究にあります。
- Trinity(トリニティ): 軽量で進化的に最適化された「コーディネーター」が、複数のLLMを複数ターンにわたって指揮します。各モデルに Thinker(思考役)・Worker(実行役)・Verifier(検証役)といった役割を割り当て、タスクに応じて適応的に委譲します。
- Conductor(コンダクター): 強化学習で訓練され、自然言語による協調戦略を自ら発見します。人手で設計したワークフローに頼らず、非自明だが効率的な協調パターンをモデル自身が学習します。
Fugu 自体も、「いつ委譲し、どのように専門家の出力を組み合わせるか」を理解することに特化した言語モデルです。
関連研究: Sakana Fugu テクニカルレポート(arXiv:2606.21228)、Trinity(arXiv:2512.04695, ICLR 2026)、Conductor(arXiv:2512.04388, ICLR 2026)
FuguとFugu Ultraの違い
Fugu には2つのバリエーションがあります。
| モデル | 特徴 | 想定用途 |
|---|---|---|
| Fugu | 性能と低レイテンシのバランス型 | 日常業務、コーディング、コードレビュー、対話型サービス |
| Fugu Ultra | 回答品質を最大化。より深いエージェントプールを協調させる | 難度の高い多段階の問題 |
Fugu Ultra は、エンジニアリング・科学・推論の各ベンチマークで Anthropic の Fable 5 や Mythos Preview と「肩を並べる」水準とされています。
Fuguのベンチマーク性能
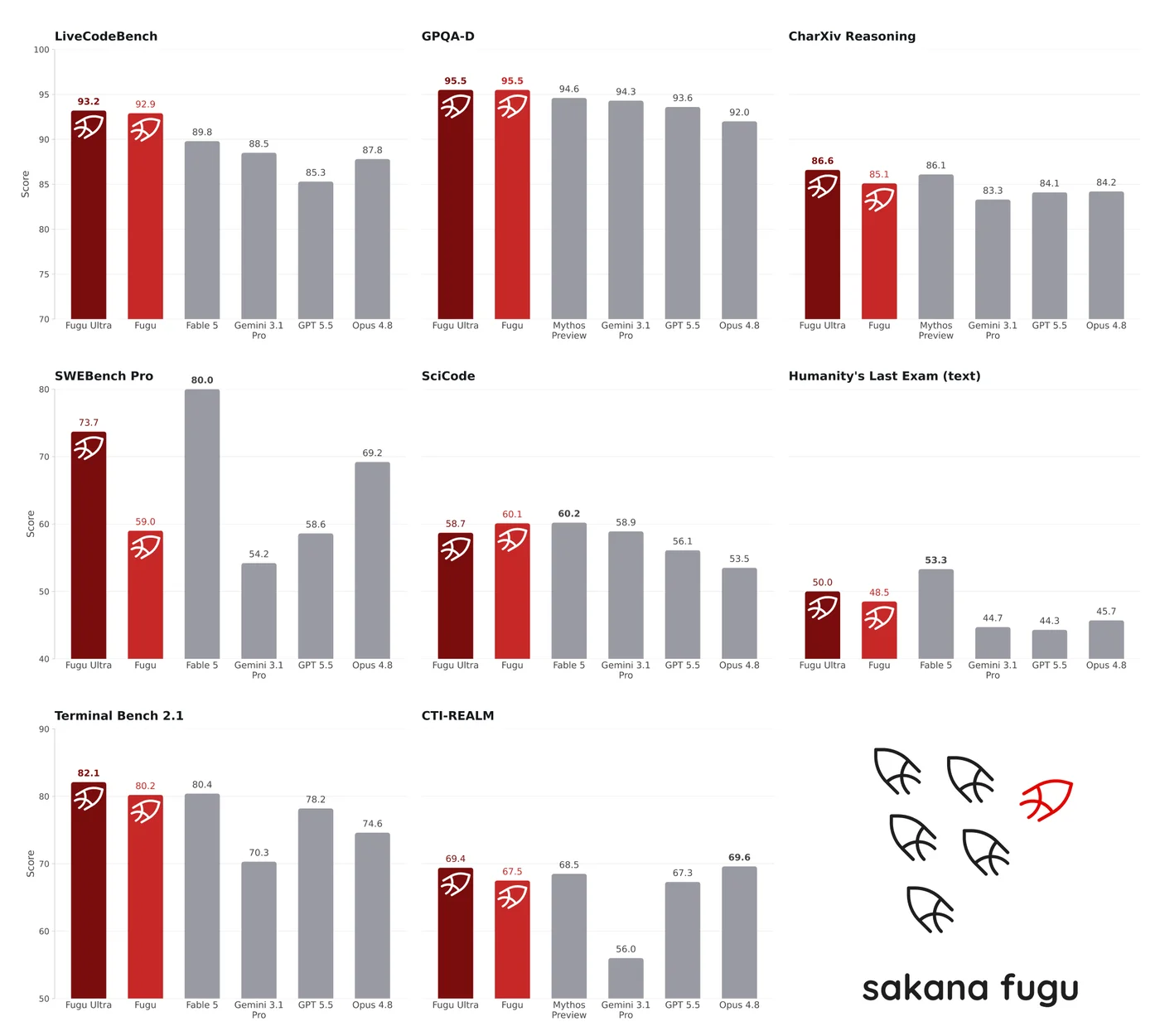
下表は、Fugu / Fugu Ultra と Opus 4.8・Gemini 3.1 Pro・GPT 5.5 を比較した公式ベンチマークです(数値は公式表より引用)。
| ベンチマーク | 分野 | Fugu | Fugu Ultra | Opus 4.8 | Gemini 3.1 Pro | GPT 5.5 |
|---|---|---|---|---|---|---|
| SWE Bench Pro | エージェント型コーディング | 59.0 | 73.7 | 69.2 | 54.2 | 58.6 |
| TerminalBench 2.1 | エージェント型コーディング | 80.2 | 82.1 | 74.6 | 70.3 | 78.2 |
| LiveCodeBench | コーディング | 92.9 | 93.2 | 87.8 | 88.5 | 85.3 |
| LiveCodeBench Pro | コーディング | 87.8 | 90.8 | 84.8 | 82.9 | 88.4 |
| Humanity's Last Exam | 多分野推論 | 47.2 | 50.0 | 49.8 | 44.4 | 41.4 |
| CharXiv Reasoning | 図表推論 | 85.1 | 86.6 | 84.2 | 83.3 | 84.1 |
| GPQA-D | 科学 | 95.5 | 95.5 | 92.0 | 94.3 | 93.6 |
| SciCode | 科学コーディング | 60.1 | 58.7 | 53.5 | 58.9 | 56.1 |
| τ³ Banking | 金融エージェント | 21.7 | 20.6 | 20.6 | 8.4 | 20.6 |
| Long Context Reasoning | 長文脈推論 | 74.7 | 73.3 | 67.7 | 72.7 | 74.3 |
| MRCRv2 | 長文脈検索 | 86.6 | 93.6 | 87.9 | 84.9 | 94.8 |
GPQA-D(95.5)や LiveCodeBench(93.2)など多くの項目で最高スコアを記録し、特に SWE Bench Pro では Fugu Ultra が 73.7 と Opus 4.8(69.2)を上回ります。複数モデルを束ねるアプローチでありながら、単一のフロンティアモデルに匹敵・凌駕する性能を示している点が注目されます。
表の引用元: Sakana AI公式発表(2026年6月22日)
実際のユースケースとユーザーの声
ベータ期間中、Fugu は自動データサイエンス研究、論文の再現、サイバーセキュリティ分析、コードレビュー、特許・文献調査などに活用されました。公式に紹介された声を一部抜粋します。
- コードレビュー: 「コードレビューでは、Fugu Ultra は GPT-5.5 より明確に優れていた。競合が3件しか見つけられなかった問題を、Fugu は20件以上指摘した」(ソフトウェアエンジニア)
- 長時間セッションの安定性: 「出力品質はトップのフロンティアモデルと同等。加えて、長いセッションでも人格(ペルソナ)が際立って安定していた」(エンタープライズ基盤の責任者)
- セキュリティ評価: 「1つのスコープ指示だけで、Fugu は偵察・XSS/SQLi チェック・認証レビュー・レポート作成まで、セキュリティ評価を端から端まで自走した」(セキュリティエンジニア)
このほか、ルービックキューブのソルバー生成、機械系CAD設計、目隠しチェス(エキスパート級)、株式トレード分析(平均リターン +19.43% を達成)など、多段階の難タスクで Gemini 3.1 Pro・Opus 4.8・GPT 5.5 を上回ったとの報告もあります。
Fuguの料金
Fugu はサブスクリプションと従量課金(ペイ・アズ・ユー・ゴー)の2形態で提供されます。
サブスクリプション
| プラン | 月額 | 利用量の目安 |
|---|---|---|
| Standard | $20 | 基準 |
| Pro | $100 | Standard の約10倍 |
| Max | $200 | Standard の約30倍 |
従量課金(Fugu Ultra / モデルID: fugu-ultra-20260615、100万トークンあたり)
| 項目 | 料金 | 272Kコンテキスト超 |
|---|---|---|
| 入力 | $5 | $10 |
| 出力 | $30 | $45 |
| キャッシュ入力 | $0.50 | $1.00 |
公式は「複数のエージェントが動作していても料金を積み上げることはなく、関与した最上位モデルに基づく単一レートのみを支払う」としています。
Fuguの使い方
Sakana Fugu のプロダクト概要は、以下のカードからも確認できます。
- API: OpenAI 互換のAPIとして提供され、両モデル(Fugu / Fugu Ultra)に単一エンドポイントからアクセスできます。
- コンソール/登録:
console.sakana.aiからサインアップして利用を開始できます。 - エージェントプールの設定: 利用したくない特定モデル・プロバイダーをプールから除外するなど、構成をカスタマイズできます。
ai-best-search では、Fugu が内部で束ねる対象にもなりうる主要モデルも紹介しています。
利用上の注意
- 提供地域: 現時点で EU / EEA では利用できません。
- モデル更新のタイミング: 新しいフロンティアモデルの登場から約2週間後を目安に、プール内のモデルが更新される見込みです。
- 今後の予定: エージェントプールの拡張(オープンモデルや Sakana 独自モデルの追加)、長時間タスクの協調強化、ユーザーによる挙動制御の拡充が予定されています。
Sakana Fuguに関するよくある質問(FAQ)
Sakana Fuguは1つのモデルですか?
ユーザーから見れば1つのAPI/1つのモデルのように使えますが、内部では複数の専門LLMを動的に束ねて協調させる「マルチエージェント基盤」です。
FuguとFugu Ultraはどう違いますか?
Fugu は性能とレイテンシのバランス型で日常業務向け、Fugu Ultra はより深いエージェントプールを協調させて回答品質を最大化する難問向けです。
Fuguは特定ベンダーに依存しますか?
いいえ。複数モデルを束ねる設計のため、あるプロバイダーが使えなくなっても経路を切り替えてフロンティア級の性能を維持できます。これが Sakana の掲げる「AI主権」の考え方です。
Fuguの料金はどのくらいですか?
サブスクは Standard $20 / Pro $100 / Max $200(月額)。従量課金は Fugu Ultra で入力 $5・出力 $30(100万トークンあたり。272Kコンテキスト超は入力 $10・出力 $45)です。複数エージェントが動いても料金は積み上がりません。
FuguはどのAPIと互換ですか?
OpenAI 互換のAPIとして提供されます。console.sakana.ai から登録して利用を開始できます。
日本でも使えますか?
EU / EEA を除く地域で利用できます。日本からの利用も可能です。
まとめ
- Sakana Fugu は、複数のLLMを動的に束ねて1つの OpenAI 互換APIとして提供するマルチエージェント基盤(2026年6月22日 一般提供開始)。
- Trinity・Conductor(ICLR 2026)の研究を基盤に、モデル自身が効率的な協調パターンを学習。
- Fugu / Fugu Ultra は SWE Bench Pro 73.7、GPQA-D 95.5、LiveCodeBench 93.2 など、単一フロンティアモデルに匹敵・凌駕する性能。
- 料金はサブスク $20〜、従量課金は入力 $5 / 出力 $30(100万トークンあたり)。複数エージェントでも料金は積み上がらない。
- 特定ベンダー依存を避けられる「AI主権」志向が、フロンティアモデルの供給リスクが高まる今、大きな注目を集めています。
複数モデルを束ねる新発想の Fugu を、自分の業務やプロダクトに活かしていきましょう。