What Is Sakana AI Fugu | A Deep Dive into the Multi-Agent API That Orchestrates the World's Best Models — Performance, Pricing, and How to Use It
A guide to Fugu, released by Sakana AI on June 22, 2026. Covers how this multi-agent platform dynamically orchestrates multiple LLMs behind a single API, the benchmark performance of Fugu and Fugu Ultra, pricing, how to use it, and the unique advantage of avoiding single-vendor dependency — all backed by official data.
Image source: Sakana AI, "Sakana Fugu" official page. All figures in this article are reproduced from Sakana AI's official website.
On June 22, 2026, Sakana AI publicly launched Fugu, a new AI platform that dynamically bundles multiple large language models (LLMs) and serves them through a single API. Rather than relying on a single frontier model, Fugu orchestrates several world-class models behind the scenes and behaves as if it were one unified model — and that is its defining characteristic.
This article explains how Sakana Fugu works, the benchmark performance of Fugu and Fugu Ultra, pricing, how to use it, and its unique value proposition: freeing you from dependence on any single vendor — all backed by official announcement data.
The data and figures in this article are sourced from Sakana AI's official announcement (June 22, 2026) and the Fugu product page.
What Is Sakana Fugu?
Sakana Fugu is a multi-agent orchestration platform developed by Sakana AI. To the user, it behaves as a single API (and an OpenAI-compatible one at that), while internally it dynamically calls on multiple specialist models (agents) depending on the task, automatically handling role assignment, delegation, verification, and integration.
- Use it like a single model: All the complexity of model selection and delegation is handled internally, so you can use it without ever worrying about that complexity.
- Dynamically bundles models: It selects the best model from a "pool" of agents and can even call Fugu itself recursively when needed.
- Avoids vendor lock-in: If a particular provider restricts access, Fugu can reroute to a different model and keep going.
- Stable persona across long sessions: It maintains consistent responses and a consistent persona even over extended interactions.
After a beta with roughly 500 early users, Fugu reached general availability (GA) on June 22, 2026.
Why Fugu Matters Right Now
Part of what makes Fugu so timely is that the supply of frontier models has begun to face geopolitical risk. For example, Anthropic's latest models, Fable 5 and Mythos 5, had their access abruptly suspended in June 2026 by a U.S. government export-control directive (for details, see our Claude Fable 5 explainer).
Fugu is positioned as a practical answer to this kind of "single-vendor dependency risk." Because it is designed to bundle multiple models, even if one provider becomes unavailable, Fugu can reshuffle its agent pool and maintain frontier-grade performance — and this is the essence of the "AI sovereignty" that Sakana champions.
How Fugu Works (Multi-Agent Orchestration)
As the diagram at the top illustrates, Fugu acts as a "conductor" that bundles a pool of LLMs (both closed and open models, as well as Fugu itself) and routes each task to the most suitable model. At its core are two research papers that Sakana AI presented at ICLR 2026.
- Trinity: A lightweight, evolutionarily optimized "coordinator" that directs multiple LLMs across multiple turns. It assigns each model a role such as Thinker, Worker, or Verifier, and delegates adaptively based on the task.
- Conductor: Trained with reinforcement learning, it discovers its own collaboration strategies expressed in natural language. Rather than relying on hand-designed workflows, the model itself learns non-obvious yet efficient patterns of collaboration.
Fugu itself is also a language model specialized in understanding when to delegate and how to combine the outputs of its specialists.
Related research: Sakana Fugu technical report (arXiv:2606.21228), Trinity (arXiv:2512.04695, ICLR 2026), Conductor (arXiv:2512.04388, ICLR 2026)
Fugu vs. Fugu Ultra
Fugu comes in two variations.
| Model | Characteristics | Intended Use |
|---|---|---|
| Fugu | Balances performance with low latency | Everyday work, coding, code review, conversational services |
| Fugu Ultra | Maximizes answer quality by orchestrating a deeper pool of agents | Difficult, multi-step problems |
Fugu Ultra is said to stand shoulder to shoulder with Anthropic's Fable 5 and Mythos Preview across engineering, science, and reasoning benchmarks.
Fugu Benchmark Performance
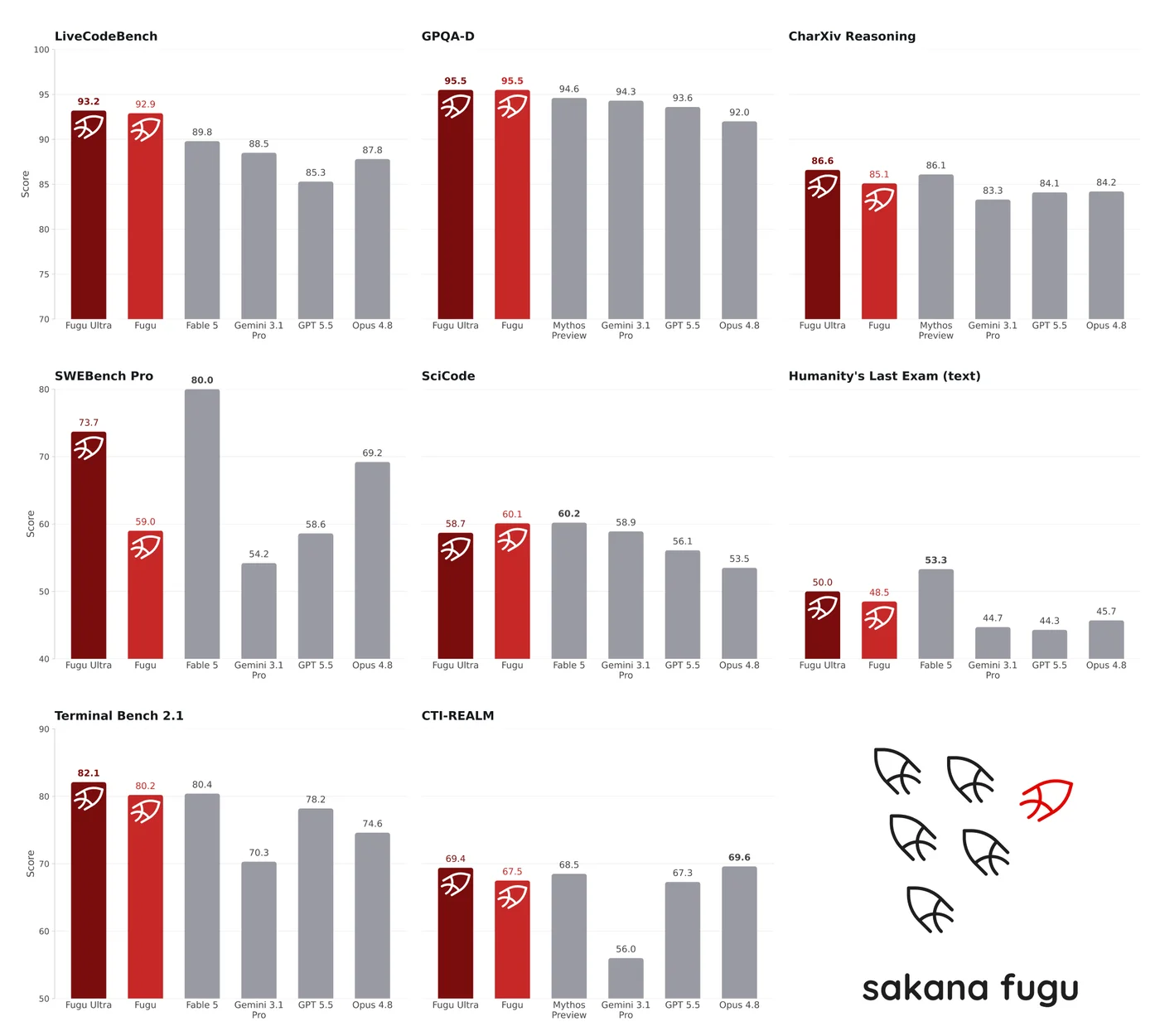
The table below is the official benchmark comparing Fugu / Fugu Ultra with Opus 4.8, Gemini 3.1 Pro, and GPT 5.5 (figures are quoted from the official table).
| Benchmark | Domain | Fugu | Fugu Ultra | Opus 4.8 | Gemini 3.1 Pro | GPT 5.5 |
|---|---|---|---|---|---|---|
| SWE Bench Pro | Agentic coding | 59.0 | 73.7 | 69.2 | 54.2 | 58.6 |
| TerminalBench 2.1 | Agentic coding | 80.2 | 82.1 | 74.6 | 70.3 | 78.2 |
| LiveCodeBench | Coding | 92.9 | 93.2 | 87.8 | 88.5 | 85.3 |
| LiveCodeBench Pro | Coding | 87.8 | 90.8 | 84.8 | 82.9 | 88.4 |
| Humanity's Last Exam | Multi-domain reasoning | 47.2 | 50.0 | 49.8 | 44.4 | 41.4 |
| CharXiv Reasoning | Figure reasoning | 85.1 | 86.6 | 84.2 | 83.3 | 84.1 |
| GPQA-D | Science | 95.5 | 95.5 | 92.0 | 94.3 | 93.6 |
| SciCode | Scientific coding | 60.1 | 58.7 | 53.5 | 58.9 | 56.1 |
| τ³ Banking | Financial agents | 21.7 | 20.6 | 20.6 | 8.4 | 20.6 |
| Long Context Reasoning | Long-context reasoning | 74.7 | 73.3 | 67.7 | 72.7 | 74.3 |
| MRCRv2 | Long-context retrieval | 86.6 | 93.6 | 87.9 | 84.9 | 94.8 |
Fugu posts the top score on many items, including GPQA-D (95.5) and LiveCodeBench (93.2), and on SWE Bench Pro in particular, Fugu Ultra's 73.7 surpasses Opus 4.8 (69.2). What stands out is that despite being an approach that bundles multiple models, it delivers performance that rivals or exceeds a single frontier model.
Table source: Sakana AI's official announcement (June 22, 2026)
Real-World Use Cases and User Feedback
During the beta period, Fugu was used for automated data-science research, paper reproduction, cybersecurity analysis, code review, patent and literature search, and more. Here are some of the officially highlighted comments.
- Code review: "On code review, Fugu Ultra was clearly better than GPT-5.5. On a problem where competitors found only three issues, Fugu flagged more than twenty." (Software engineer)
- Long-session stability: "Output quality was on par with the top frontier models. On top of that, its persona stayed remarkably stable even over long sessions." (Head of an enterprise platform)
- Security assessment: "With just a single scope instruction, Fugu ran an end-to-end security assessment on its own — reconnaissance, XSS/SQLi checks, authentication review, and report writing." (Security engineer)
Beyond these, there are also reports that Fugu outperformed Gemini 3.1 Pro, Opus 4.8, and GPT 5.5 on difficult multi-step tasks such as generating a Rubik's Cube solver, mechanical CAD design, blindfold chess (at an expert level), and stock-trading analysis (achieving an average return of +19.43%).
Fugu Pricing
Fugu is offered in two forms: subscription and pay-as-you-go.
Subscription
| Plan | Monthly | Approximate Usage |
|---|---|---|
| Standard | $20 | Baseline |
| Pro | $100 | About 10× Standard |
| Max | $200 | About 30× Standard |
Pay-as-you-go (Fugu Ultra / model ID: fugu-ultra-20260615, per million tokens)
| Item | Price | Above 272K context |
|---|---|---|
| Input | $5 | $10 |
| Output | $30 | $45 |
| Cached input | $0.50 | $1.00 |
Officially, "even when multiple agents are running, charges do not stack up — you pay only a single rate based on the top-tier model involved."
How to Use Fugu
You can also check out the Sakana Fugu product overview from the card below.
- API: Offered as an OpenAI-compatible API, with access to both models (Fugu / Fugu Ultra) from a single endpoint.
- Console / sign-up: You can sign up and get started at
console.sakana.ai. - Configuring the agent pool: You can customize the configuration, for example by excluding specific models or providers you don't want to use from the pool.
ai-best-search also covers the major models that Fugu may bundle internally.
Things to Keep in Mind
- Availability by region: It is currently not available in the EU / EEA.
- Model update timing: Models in the pool are expected to be updated roughly two weeks after a new frontier model is released.
- Roadmap: Plans include expanding the agent pool (adding open models and Sakana's own models), strengthening collaboration on long-running tasks, and giving users more control over its behavior.
Frequently Asked Questions About Sakana Fugu (FAQ)
Is Sakana Fugu a single model?
From the user's perspective you can use it like a single API / a single model, but internally it is a "multi-agent platform" that dynamically bundles and orchestrates multiple specialist LLMs.
How do Fugu and Fugu Ultra differ?
Fugu balances performance and latency and is geared toward everyday work, while Fugu Ultra orchestrates a deeper pool of agents to maximize answer quality and is geared toward difficult problems.
Does Fugu depend on a specific vendor?
No. Because it is designed to bundle multiple models, even if one provider becomes unavailable it can reroute and maintain frontier-grade performance. This is the essence of the "AI sovereignty" Sakana champions.
How much does Fugu cost?
Subscriptions are Standard $20 / Pro $100 / Max $200 (per month). Pay-as-you-go for Fugu Ultra is $5 input and $30 output (per million tokens; above 272K context, $10 input and $45 output). Charges do not stack up even when multiple agents are running.
Which API is Fugu compatible with?
It is offered as an OpenAI-compatible API. You can sign up and get started at console.sakana.ai.
Can I use it in my country?
It is available in all regions except the EU / EEA.
Summary
- Sakana Fugu is a multi-agent platform that dynamically bundles multiple LLMs and serves them through a single OpenAI-compatible API (general availability began June 22, 2026).
- Built on the Trinity and Conductor research (ICLR 2026), the model itself learns efficient patterns of collaboration.
- Fugu / Fugu Ultra deliver performance that rivals or exceeds a single frontier model, with results such as SWE Bench Pro 73.7, GPQA-D 95.5, and LiveCodeBench 93.2.
- Pricing starts at $20 for a subscription, with pay-as-you-go at $5 input / $30 output (per million tokens). Charges don't stack up even with multiple agents.
- Its "AI sovereignty" orientation — freeing you from dependence on a single vendor — is drawing major attention at a time when supply risk for frontier models is rising.
Put Fugu's new approach to bundling multiple models to work in your own job or product.